


Como todos sabemos, los datos están tomando un papel fundamental en los negocios, sin importar sector o servicio que ofrezcan.
Se realizan todo tipo de modelos descriptivos/predictivos por diversos motivos: Captación de Clientes, churn abundante, oferta, recursos humanos…
Por este motivo las empresas deben de tener una buena arquitectura en sus bases de datos y un equipo experto que la mantenga siempre en buenas condiciones y a poder ser muy centralizada, porque, como veremos en este artículo, todo gira en torno al dato, y la calidad de ese data warehouse va a ser clave para los inputs de las grandes estrategias que aborden sus departamentos.
Todo plan estratégico, tiene un fundamento teórico detrás, pero toda decisión debe estar también fundamentada en un análisis profundo que plantee unas mínimas medidas de rendimiento esperado.
Por este motivo, cuando hablamos de la era de los datos, de la época de la digitalización o incluso de la cuarta revolución industrial, lo hacemos con una visión prospectiva del momento en el que vivimos.
Las grandes compañías, líderes en sus respectivos sectores, invierten en infraestructuras tecnológicas muy adecuadas para la explotación y mantenimiento de todos los datos que les aportan sus clientes, incluso de aquellos datos que compran a otras empresas. Pero no sólo invierten en infraestructuras, también lo hacen en personal con expertise que mantengan un nivel de calidad del dato, como hemos dicho, crucial, para que posteriormente los especialistas estadísticos, matemáticos o econométricos aporten valor con los datos al negocio.
Desafortunadamente, empresas con menos recursos o con una cultura empresarial no tan tecnológica tienen problemas de adaptación a la nueva era digital, y sin hacer mención a los países menos desarrollados en los que aún se ve muy lejos una empresa con datos centralizados, robustos y con alto grado de automatización en sus procesos.
Volviendo a los proyectos que sustentan las decisiones estratégicas, son a menudo proyectos realizados por empresas externas especializadas o por equipos/departamentos internos dedicados a la explotación y análisis de los datos. Pero independientemente de quién lo lleve a cabo, estos proyectos no son sencillos y suelen tener una metodología bastante clara y definida, la cual resumimos:
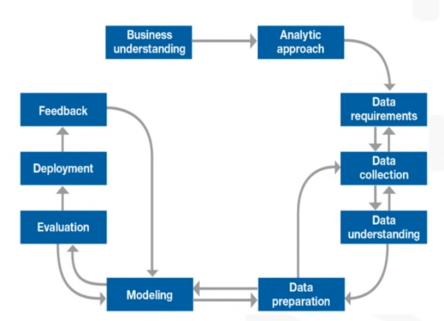
– Conceptualizar el negocio. El primer paso es tener claro cuáles son los objetivos del proyecto. Entender el negocio es fundamental y no es cosa sólo de los expertos en negocio. Hoy en día, los científicos de datos deben conocerlo igual de bien que los expertos.
– Definir el enfoque analítico. Dependiendo del objetivo, la estrategia de modelado será una u otra. Se requieren modelos predictivos, descriptivos, diagnósticos…
– Delimitar la fase de requerimiento de datos. Debemos preguntarnos, ¿Qué datos vamos a necesitar? ¿Qué fuentes debemos de atacar? ¿Tenemos datos internos, los complementaremos con la compra a externos?
– Recopilación de los datos. Debemos de centralizar toda la información adquirida de todas las fuentes. ¿Necesitamos otra fuente? Los científicos de datos expertos, no sólo se conforman con los datos obtenidos internamente, o con aquellos que se puedan comprar a externos, sino que hay datos públicos potencialmente explotables, robustos y con garantías que son actualizados en tiempo real en internet, por ejemplo, datos de meteorología, y que automatizan su explotación y tratamiento.
– Comprensión de los datos. Es crítico entender de qué datos disponemos, qué significan y que nos aportan.
– Preparación de los datos: Debemos someter la base de datos a un proceso de limpieza de datos anómalos, erróneos o no coherentes en el contexto, y hacer un tratamiento especial si fuera necesario para los datos omitidos.
– Pre-Modelización: Es el momento de analizar variable por variable, su potencial para el modelo. Para ello se realizan estadísticos descriptivos, análisis de poder discriminante, correlaciones…
– Modelización: Programar en un lenguaje estadístico (R, TOL, SAS, SPSS…) según los resultados de la pre-modelización. Mi opinión es siempre aportarle conocimiento de negocio a los datos, por ello, la utilización de modelos bayesianos (basados en estadística bayesiana en lugar de la tradicional) son claves (En futuos Post entraremos en detalle).
– Evaluación del modelo: Realizar test de evaluación del modelo, tablas de contingencia, curvas ROC, estadísticos, test de bondad, robustez… Hay una amplia gama de métricas a la hora de evaluar la calidad de un modelo, para posteriormente seguir ajustándolo.
– Análisis previo de los resultados. Comenzar a sacar conclusiones de los outputs de los modelos.
– Implementación del modelo automatizado: Se debe de realizar una herramienta que esté automatizada totalmente, desde un ETL hasta la estimación y evaluación del modelo. Debe de establecerse una política de mantenimiento en el modelo que detecte cualquier desviación de las estimaciones o de los estadísticos de evaluación. De esta manera, se dotará de un sistema de alarmas para detectar desajustes y ser capaces de corregirlos.
– Retroalimentación del modelo: El modelo debe aprender y ser inteligente. Debe poderse adaptar a los cambios que puedan surgir y poder mejorar la estimación y los ajustes.
– Explotación del Modelo: Toma de decisiones fundamentadas en los resultados del modelo.
Como vemos en el esquema, ciertas etapas de la construcción deben de ser iterativas para así hacer un modelo más preciso y ajustado.
Hay dos cosas obvias pero a tener en cuenta:
1) El modelo no es efectivo si no se elaboran estrategias a partir de sus resultados.
2) El modelo siempre necesitará un mantenimiento si se desea conservar en el tiempo, ya que deben de saltar alarmas cuando los parámetros se desajusten y deba de actualizarse en algún momento.
Como vemos, la calidad del dato es fundamental en el proceso. Si el dato es erróneo, o no se tiene la suficiente información, el nivel de incertidumbre del modelo será demasiado alto.
También hay que destacar, que aunque parece que la mayor parte del tiempo dedicado al proyecto se invertirá en el modelado, esto pocas veces es así. La parte de ETL, dependiendo de cómo estén las fuentes de datos, puede ser un trabajo tan costoso, que sea un gran proyecto dentro este. Las fuentes pueden estar muy dispersas, que dependientes de diferentes equipos muy independientes… Esto es como consecuencia de lo que comentaba al principio: un data warehouse bien estructurado, con toda la información y buena infraestructura, ahorra tiempo, presupuesto y recursos en proyectos orientados a la toma de decisiones. Además, mejorará sustancialmente los resultados.
Espero comenten, opinen, y les haya aportado.
Un abrazo.
Pedro José Mendoza.
